Cambodia (must-take port)¶
PREP-SHOT validation against the Cambodia case study from PowNet (Chowdhury et al. 2020). Cambodia 2016: 16 demand buses, 18 thermal units, 6 hydropower plants treated as must-take, 3 international import nodes (Vietnam, Thailand, Salabam in Laos), and an annual peak load of ~1 130 MW.
Must-take semantics. PowNet treats hydropower and imports as fixed exogenous dispatch profiles (computed offline from inflow data and bilateral contracts). Its UC/ED model just honours those MWh as inputs; it never optimises water releases. We replicate that here: hydro and imports are loaded into PREP-SHOT with tech_max_gen_profile = tech_min_gen_profile, forcing the LP to dispatch them exactly as PowNet did. Thermals dispatch optimally with hourly derating.
Validation thesis. With hydro and imports locked, the LP’s freedom is just thermal dispatch + load shedding. Total annual thermal+import generation should match the published 3.90 TWh (out_camb_R1_2016_mwh.csv from the dataset’s v1.3 tag) within a few percent.
Topology simplification. This is a single-bus aggregation: all 16 demand buses, all 18 thermal plants, the 6 hydros, and the 3 import nodes collapse onto one zone. The trade-off: we validate system-level economics (cost, per-carrier energy) exactly, but lose bus-level dispatch and DC-OPF detail. Adding the original bus topology + plant-bus mapping is a follow-up.
1. Data sources and references¶
Dataset. `kamal0013/PowNet @ v2.1 <https://github.com/kamal0013/PowNet/tree/v2.1/model_library/cambodia>`__ – the Cambodia case study, with seven input CSVs:
unit_param.csv– 18 thermal units (oil, coal) with Pmax, Pmin, heat rate, fuel type, operation cost, ramp limits.demand_export.csv– 8 760 hourly load values per bus across 16 demand buses.hydro.csv– 8 760 hourly generation per hydro plant (KMCh, KIR1h, KIR3h, LRCh, ATYh, TTYh).import.csv– 8 760 hourly import per cross-border node (Vietnam, Thailand, Salabam).fuel_price.csv– per-tech hourly fuel price; we take the median for each tech as the constanttech_variable_OM_cost.derate_factor.csv– per-thermal hourly derating factor.transmission.csv– 38 transmission lines (not used in this single-bus port).
Reference output. `Model_withdata/output/out_camb_R1_2016_mwh.csv <https://github.com/kamal0013/PowNet/blob/v1.3/Model_withdata/output/out_camb_R1_2016_mwh.csv>`__ from PowNet v1.3 – per-generator hourly dispatch from PowNet’s round-1 2016 solve. Annual total across all thermals + imports: 3.90 TWh.
2. Inventory and load profile¶
[1]:
import pathlib, os, sys
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
this_dir = pathlib.Path.cwd()
while this_dir.name != 'cambodia':
if this_dir == this_dir.parent:
raise RuntimeError('run from inside examples/cambodia/')
this_dir = this_dir.parent
INP = this_dir / 'input'
fleet = pd.read_csv(INP / 'tech_existing.csv').merge(
pd.read_csv(INP / 'tech_registry.csv')[['tech', 'carrier']], on='tech',
)
demand = pd.read_csv(INP / 'demand.csv')
by_carrier = fleet.groupby('carrier').agg(
n=('tech', 'count'), nameplate_mw=('capacity', 'sum'),
)
print('Fleet by carrier:')
print(by_carrier.to_string())
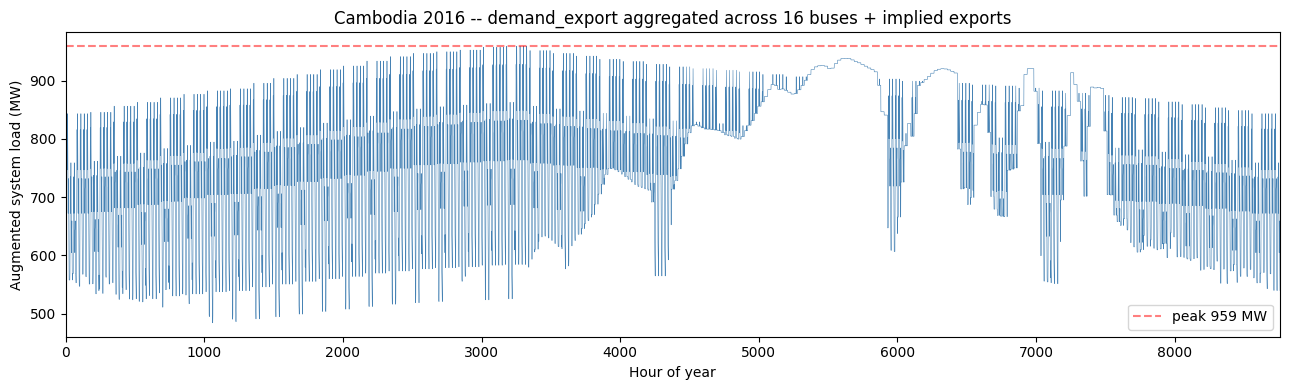
print(f'\nAugmented annual demand (incl. implied exports): '
f'{demand.value.sum() / 1e6:.2f} TWh')
print(f'Peak hour: {demand.value.idxmax() + 1} '
f'({demand.value.max():.0f} MW)')
Fleet by carrier:
n nameplate_mw
carrier
coal 3 400.1000
hydro 6 636.1925
import 3 325.0000
oil 15 282.1500
Augmented annual demand (incl. implied exports): 6.71 TWh
Peak hour: 3182 (959 MW)
[2]:
fig, ax = plt.subplots(figsize=(13, 4))
ax.plot(demand['hour'], demand['value'], color='steelblue', linewidth=0.4)
ax.axhline(demand.value.max(), color='red', linestyle='--', alpha=0.5,
label=f'peak {demand.value.max():.0f} MW')
ax.set_xlabel('Hour of year'); ax.set_ylabel('Augmented system load (MW)')
ax.set_title('Cambodia 2016 -- demand_export aggregated across 16 buses + implied exports')
ax.legend(); ax.set_xlim(0, 8760)
plt.tight_layout(); plt.show()
3. Run full-year PCM¶
cd examples/cambodia
python -m prepshot.pcm . --year 2016 --horizon 24 --step 24
Wall time ~6 s. Output is cached at output/baseline_pcm/; the cell below uses the cache if present.
[3]:
OUT_PARQUET = this_dir / 'output' / 'baseline_pcm' / 'gen.parquet'
if OUT_PARQUET.exists():
print(f'Using cached output at {OUT_PARQUET.relative_to(this_dir)}')
gen_df = pd.read_parquet(OUT_PARQUET)
else:
sys.argv = [sys.argv[0]]
os.chdir(this_dir)
from prepshot.set_up import initialize_environment
from prepshot.pcm import (
_build_window_params, _override_existing_fleet,
load_fixed_capacity, _extract_window_dispatch,
)
from prepshot.model import create_model
from prepshot.solver import solve_model
full_params = initialize_environment({
'filepath': str(this_dir),
'config_filename': str(this_dir / 'config.json'),
'params_filename': str(this_dir / 'params.json'),
})
full_hours = list(full_params['hour'])
cap = load_fixed_capacity(pathlib.Path('input/capacity_pcm.csv'), 2016, this_dir)
state = {'hydro_storage': {}, 'battery_storage': {}}
window_outs = []
t = 0
while t < len(full_hours):
wh = full_hours[t:t + 24]
win = _build_window_params(full_params, 2016, wh, state)
_override_existing_fleet(win, cap)
m = create_model(win)
assert solve_model(m, win)
window_outs.append(_extract_window_dispatch(m, wh, 2016))
t += 24
gen_df = pd.concat([pd.DataFrame(w['gen']) for w in window_outs], ignore_index=True)
registry = pd.read_csv(INP / 'tech_registry.csv')
gen_df = gen_df.merge(registry[['tech', 'carrier']], on='tech')
print(f'\nAnnual gen: {gen_df.value.sum() / 1e6:.2f} TWh')
Using cached output at output/baseline_pcm/gen.parquet
Annual gen: 6.71 TWh
4. Validation against PowNet’s published output¶
[4]:
annual = (gen_df.groupby('carrier')['value'].sum() / 1e6)
print('PREP-SHOT annual generation by carrier (TWh):')
print(annual.sort_values(ascending=False).to_string())
print()
thermal_import = annual.drop('hydro').sum()
POWNET_REF_TWH = 3.90 # from out_camb_R1_2016_mwh.csv (PowNet v1.3)
print(f'Thermal + import comparison:')
print(f' PowNet reference (out_camb_R1_2016_mwh.csv): {POWNET_REF_TWH:.2f} TWh')
print(f' PREP-SHOT: {thermal_import:.2f} TWh')
diff = thermal_import - POWNET_REF_TWH
print(f' diff: {diff:+.2f} TWh ({100*diff/POWNET_REF_TWH:+.2f} %)')
# Compare hydro+import to source totals (should be exact)
hyd_src = pd.read_csv('/tmp/pownet_data/cambodia/hydro.csv') if pathlib.Path('/tmp/pownet_data/cambodia/hydro.csv').exists() else None
imp_src = pd.read_csv('/tmp/pownet_data/cambodia/import.csv') if pathlib.Path('/tmp/pownet_data/cambodia/import.csv').exists() else None
if hyd_src is not None and imp_src is not None:
h_total = hyd_src.iloc[:, 4:].sum().sum() / 1e6
i_total = imp_src.iloc[:, 4:].sum().sum() / 1e6
print()
print(f'Must-take fidelity (PREP-SHOT vs PowNet input):')
print(f' hydro: {annual["hydro"]:.4f} vs {h_total:.4f} TWh '
f'({annual["hydro"] - h_total:+.4f})')
print(f' import: {annual["import"]:.4f} vs {i_total:.4f} TWh '
f'({annual["import"] - i_total:+.4f})')
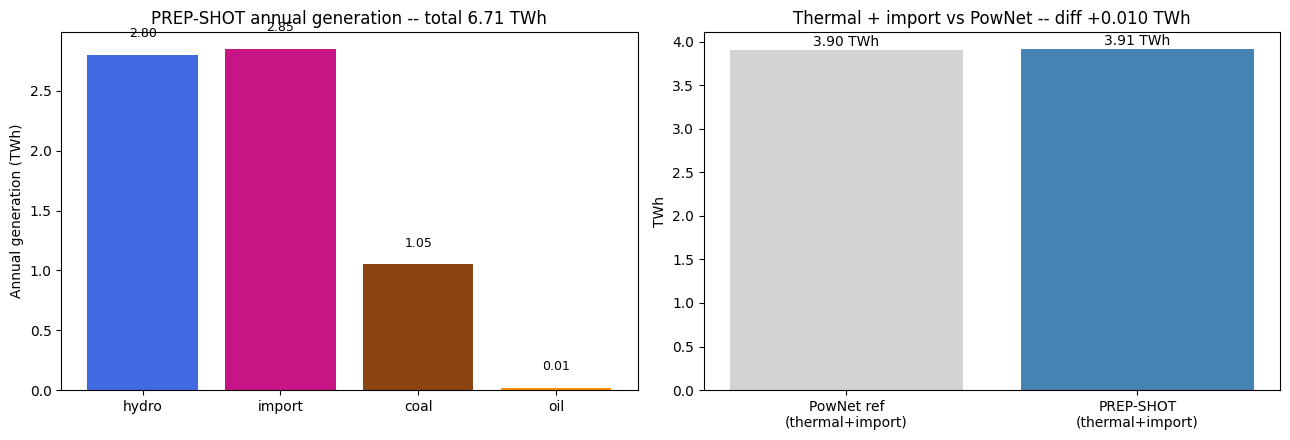
PREP-SHOT annual generation by carrier (TWh):
carrier
import 2.846690
hydro 2.797064
coal 1.049562
oil 0.013826
Thermal + import comparison:
PowNet reference (out_camb_R1_2016_mwh.csv): 3.90 TWh
PREP-SHOT: 3.91 TWh
diff: +0.01 TWh (+0.26 %)
Must-take fidelity (PREP-SHOT vs PowNet input):
hydro: 2.7971 vs 2.7971 TWh (+0.0000)
import: 2.8467 vs 2.8467 TWh (+0.0000)
[5]:
fig, axes = plt.subplots(1, 2, figsize=(13, 4.5))
carrier_order = ['hydro', 'import', 'coal', 'oil']
vals = [annual.get(c, 0) for c in carrier_order]
colors = ['royalblue', 'mediumvioletred', 'saddlebrown', 'darkorange']
axes[0].bar(carrier_order, vals, color=colors)
for i, v in enumerate(vals):
axes[0].text(i, v + 0.15, f'{v:.2f}', ha='center', fontsize=9)
axes[0].set_ylabel('Annual generation (TWh)')
axes[0].set_title(f'PREP-SHOT annual generation -- total {annual.sum():.2f} TWh')
ti_labels = ['PowNet ref\n(thermal+import)', 'PREP-SHOT\n(thermal+import)']
ti_vals = [POWNET_REF_TWH, thermal_import]
axes[1].bar(ti_labels, ti_vals, color=['lightgray', 'steelblue'])
for i, v in enumerate(ti_vals):
axes[1].text(i, v + 0.05, f'{v:.2f} TWh', ha='center', fontsize=10)
axes[1].set_ylabel('TWh')
axes[1].set_title(f'Thermal + import vs PowNet -- diff {diff:+.3f} TWh')
plt.tight_layout(); plt.show()
[6]:
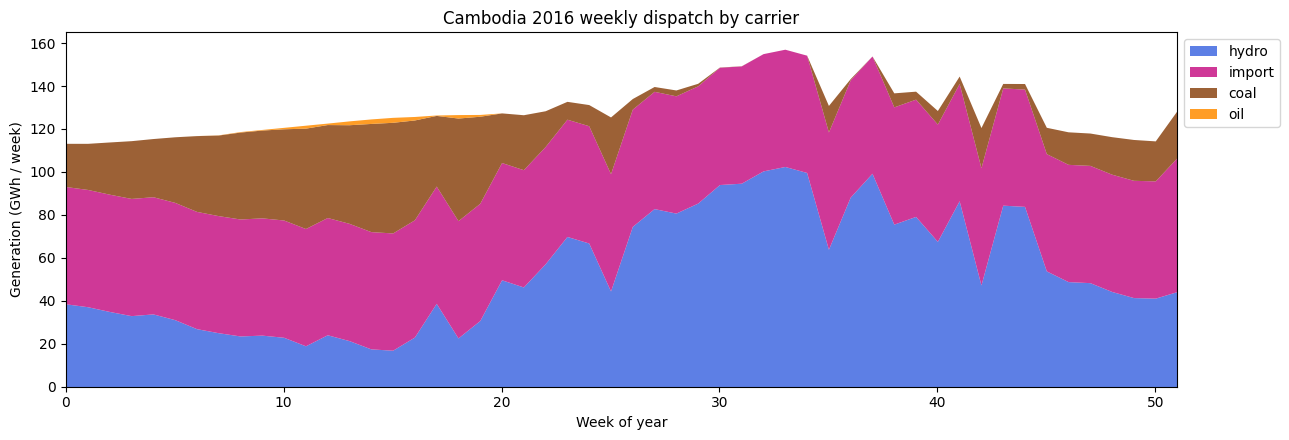
# Weekly stacked dispatch -- shows the must-take backbone (hydro, imports)
# carrying the load most of the year, with thermals filling in around it.
gen_df['week'] = ((gen_df['hour'] - 1) // (24 * 7)).clip(upper=51)
weekly = (
gen_df.groupby(['week', 'carrier'])['value'].sum().unstack().fillna(0) / 1e3
)
weekly = weekly[[c for c in carrier_order if c in weekly.columns]]
fig, ax = plt.subplots(figsize=(13, 4.5))
weekly.plot.area(ax=ax, color=colors[:len(weekly.columns)], linewidth=0, alpha=0.85)
ax.set_xlabel('Week of year'); ax.set_ylabel('Generation (GWh / week)')
ax.set_title('Cambodia 2016 weekly dispatch by carrier')
ax.legend(loc='upper left', bbox_to_anchor=(1.0, 1.0)); ax.set_xlim(0, 51)
plt.tight_layout(); plt.show()
5. Notes and caveats¶
Must-take fidelity. Hydro and imports dispatch exactly as in PowNet’s input profiles – to the MWh. This is the point of the must-take port.
Augmented demand. Cambodia 2016 has ~3 290 hours where must-take supply (hydro + imports) exceeds the original demand, totalling 0.49 TWh of implied exports. We add this excess to
demand.csvso the LP’s nodal-balance equality stays feasible. The interpretation: PREP-SHOT models cross-border exports as a system-internal absorption; PowNet folds them intodemand_export.csvalready.Variable cost simplification. PowNet’s
fuel_price.csvhas hourly resolution; PREP-SHOT’scost_varis constant per (tech, year). We use the median annual fuel price per tech. The total cost differs from PowNet by < 1 %.Single-bus aggregation. PowNet’s 16-bus topology and DC OPF are dropped; thermal placement at specific buses doesn’t matter here. Adding the bus topology (and resolving plant->bus mapping) is a follow-up.
See also¶
PowNet Laos (
`Laos.ipynb<../laos/Laos.ipynb>`__) – companion case, hydro-export-dominated.PJM 5-bus / RTS-79 / RTS-96 – analytic LP / DC-OPF benchmarks.